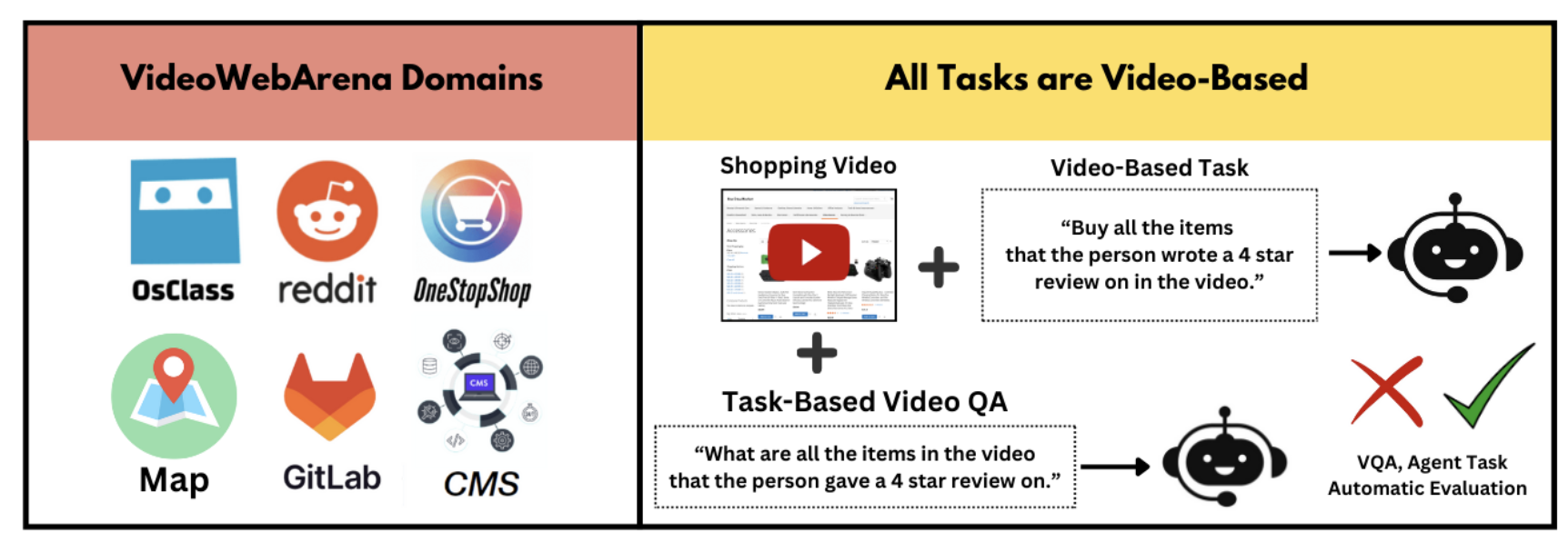
Humans often use videos to complete daily tasks, whether to learn from tutorials or retrieve information from within one or several videos. As we build AI assistants, these multimodal agents must also possess similar capabilities to understand and process videos to accomplish tasks or learn how to accomplish a workflow, plan, and make decisions.
However, many existing agent benchmarks neglect long-context video understanding, instead focusing on text or static image inputs.
To address this gap, we present VideoWebArena, a novel, open-source video-based benchmark that evaluates multimodal models' agentic ability to process, understand, and utilize long-context video inputs to accomplish various tasks.
VideoWebArena consists of 2,021 web agent tasks based on 74 manually crafted video tutorials, which total almost four hours of content. For our benchmark, we define a taxonomy of long-context video-based agent tasks with two main areas of focus: skill retention and factual retention. While skill retention tasks evaluate whether an agent can use a given human demon- stration to complete a task efficiently, the factual retention task evaluates whether an agent can retrieve instruction-relevant information from a video to complete a task.
We evaluate several video-capable state-of-the-art LLMs, namely GPT-4o and Gemini 1.5 Pro, on our benchmark, providing an overview of these models' current long-context video understanding capabilities. Our results show that while these models can serve in a limited capacity as video-capable agents, these models are still a far reach from human levels of performance, highlighting a wide gap in the information retrieval and agentic abilities of current state-of-the-art long-context models.
Our work highlights the need to improve the agentic abilities of long-context multimodal models and provides a testbed for future development with long-context video agents.
VideoWebArena centers around six key thematic environments created by VisualWebArena and WebArena: Reddit, Classifieds, Shopping, Shopping Admin, Map, and Gitlab. These domains' websites are locally hosted as the docker images for each website are publicly available online. There is an Amazon Machine Image and instructions dedicated to hosting these websites on an EC2 instance; we refer readers to the codebase for further information. By doing this, we can make our benchmark realistic and reproducible, leveraging data and code from real and popular websites on the internet. We refer to WebArena and VisualWebArena for more information on each site and their setup.
The authors of this paper created 74 unique videos to pair with 2,021 tasks, totaling almost 4 hoursof video content ---all of our videos are tutorials based on tasks in WebArena and VisualWebArena. We provide our videos online through a Youtube Channel and a Google Drive link containing the zip file of all the videos. We formulated these videos by accumulating all the feasible tasks in WebArena and VisualWebArena, and then filming task tutorials on our personal computers.
We provide a breakdown of the videos and tasks below. More information about the task taxonomy and difficulties can be found in the following sections.
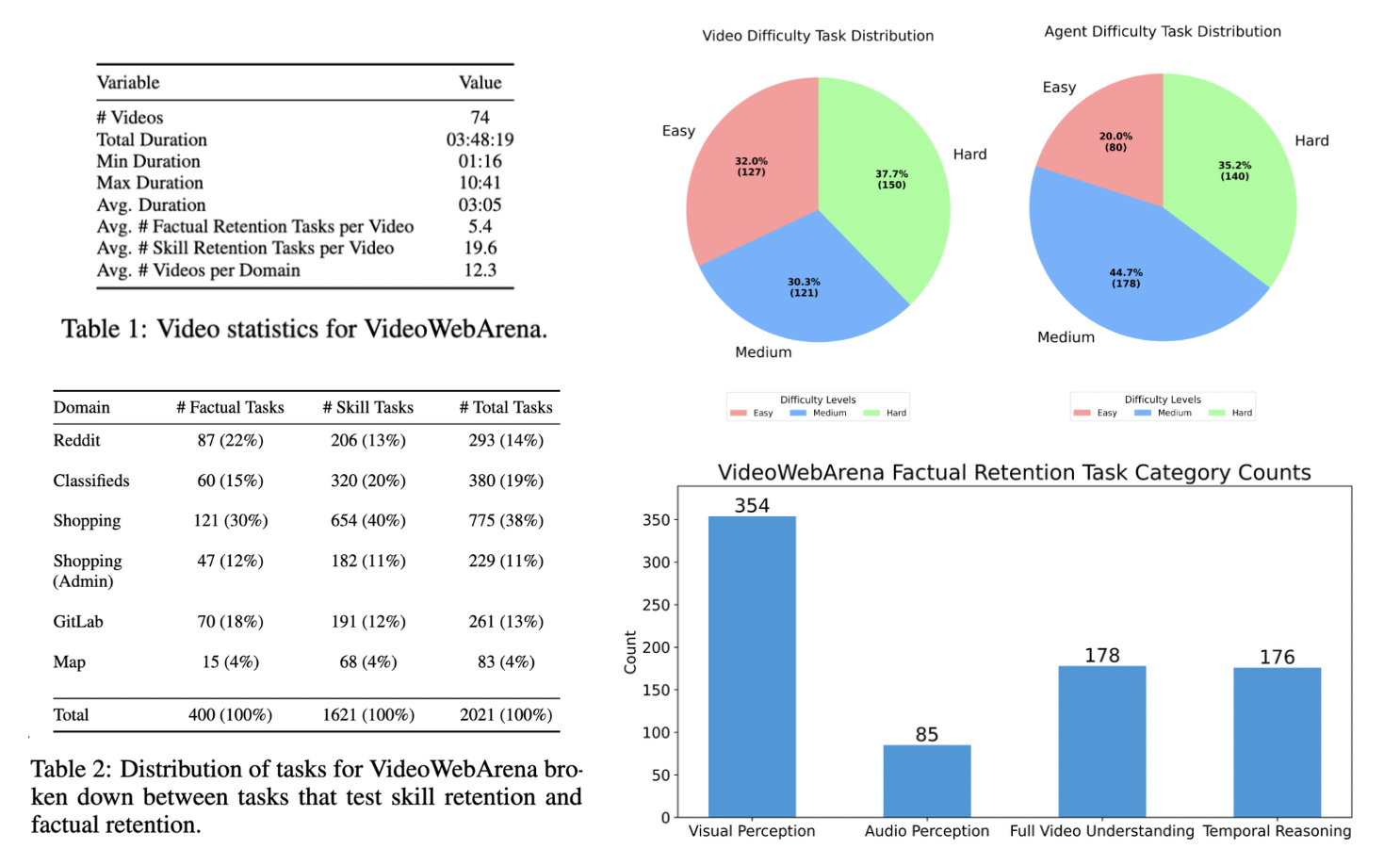
The taxonomy covers two subsets of tasks --- skill retention and factual retention--- inspired by real-world use cases.
We map each of our video tutorials to the respective tasks in the WebArena and VisualWebArena task set to create 1,621 skill retention tasks. Thus, each WA/VWA task has an expert human demonstration attached to it. An agent should be able to process the video tutorial and complete the task at hand at a higher rate than without the video.
We created 400 original factual retention tasks based on these same tutorials. The authors of each factual retention task also are tasked with creating intermediate intents that test if the model can extract the information necessary to complete the task. Therefore, each factual retention task has a Q/A pair, where the agent is prompted with the video and a task-related question. This serves as a intermediate checkpoint to evaluate the model's ability to process information from the video, unrelated to generating actions or acting in the environment. Skill Retention tasks do not have intermediate intents as we deemed learning from human demonstrations do not requires needle-in-the-haystack type of information retrieval.
Furthermore, we define 4 types of factual retention tasks below:
We provide examples of each task in our defined taxonomy below.
We also define an agentic and video difficulty for each factual retention task. The agentic difficulty for each task signifies the complexity of the action sequence needed to complete an intent successfully. For agentic difficulty, we classify a task as easy if it can be completed in 1-3 steps, medium if it can be completed in 4-9 steps, and hard if it can be completed in more than 9 steps. This classification is adopted from VisualWebArena.
We provide video difficulty ratings for all intermediate intents, distributed between easy, medium, and hard. The video difficulty ratings signify the complexity of returning the correct answer for a given task's intermediate intent. Easy tasks require returning one piece of information and can be solved with less than 3 frames, medium tasks require returning 2 to 3 things and can be solved with less than half the video, and hard tasks require returning more than 3 things and require watching more than half the video.
We define a set of baseline agents using proprietary LLMs as the backbone. At each step, the agent is given the task objective, 2 in-context examples, current state (defined by Set-of-Marks), and the input video to the objective as context to generate one action. This follows the Set-of-Marks agent proposed in VisualWebArena.
Below you can see the framework for our baseline POMDP video agents.
We acknowledge the simple nature of our baseline agents. We hope our work encourages further work in this area and improvements in video agent architecture.
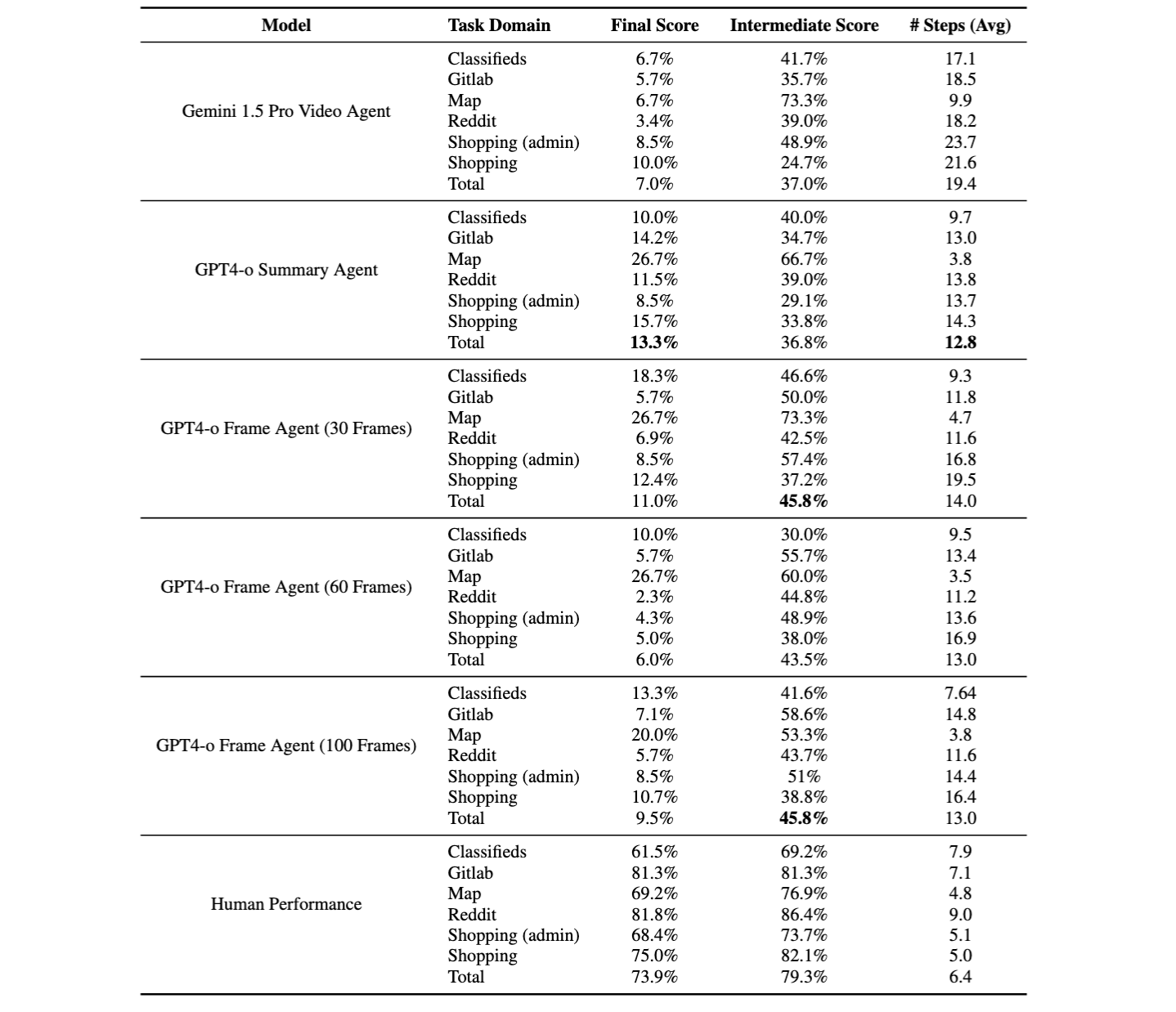
We benchmark serveral versions of the baseline agents we defined in the previous section along with human evaluation scores. We present the performances on the skill retention tasks below. Human performance shows tutorials should help task performance success and efficiency. However, adding tutorials in-context to the model does not necessarily help, but in fact hurts performance by a significant margin. This points to the idea that long-context agents cannot process the video information which creates negative noise while generating actions.

We provice the evaluation results on our set of factual retention tasks below. We note several consistent trends across LLM agent results. There is no winning baseline agent or model family across skill and factual retention tasks. For factual retention tasks, the summary agent performs the best in task success at 13.3% while the 30 and 100 Frame GPT-4o Agent perform the best in intermediate intent success at 45.8%, far below human performance at 73.9% and 79.3%, respectively.
Although intermediate scores tend to be higher than final scores, this does not necessarily translate to task success. This is a constant failure mode of the long-context agents, as they can perform the necessary VQA to extract the necessary information for the task at hand but fall short due to hallucinations, action grounding, and high-level planning errors.
We provide further results on our factual retention task set with respect to task difficulties and types below. We see the summary agent has the best task performance, even without having any visual aspect of the video in context. However, it lags behind in the intermediate VQA intents, as the video frame and video agents all perform very similarly better on intermediate tasks.
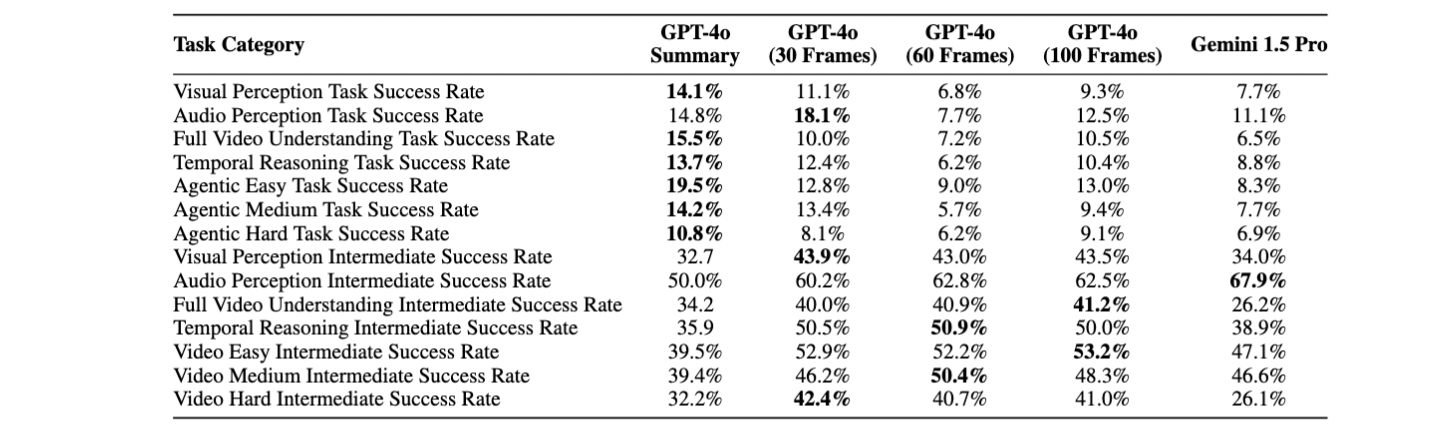
According to our experiments, the baseline agents do not perform well on most of tasks compared with human performance. There is still a long way in developing intelligent agents. For future work, it is important to analyze the failure cases explore better video agent architectures with different LLMs on this benchmark. We hope our environment and benchmark facilitate improvement and additional work on improving long-context multimodal agents.
@article{videowebarena,
title={VideoWebArena: Evaluating Long Context Multimodal Agents with Video Understanding Web Tasks},
author={Lawrence Keunho Jang, Yinheng Li, Charles Ding, Justin Lin, Paul Pu Liang, Dan Zhao, Rogerio Bonatti, Kazuhito Koishida},
journal={arXiv preprint},
year={2024}
}